

AI에는 GPU가 필수라고 할 수 있습니다. AI를 위해서는 CPU만으로는 연산 처리에 한계가 있으니까요.
하지만, GPU를 사용하더라도 단일 GPU 만으로는 요즘과 같이 처리할 데이터가 방대해진 상황에서는 한계가 있을 수 있습니다.
그래서 단일 GPU나 단일 서버의 연산 처리 능력으로는 처리하기 힘든 대규모 데이터나 복잡한 AI 시스템을 위해 다수의 GPU를 사용하여 병렬 처리를 하는 방식인 GPU 클러스터라는 개념이 나오게 된 것이구요.
GPU 클러스터에 대해서는 아래 글을 참고해 보세요.
* GPU 클러스터(GPU Cluster)의 모든 것!
GPU 클러스터를 통해서 대규모 데이터나 복잡한 AI 시스템을 위한 병렬 처리가 가능해졌지만, 여기서도 고려해야 할 사항이 있습니다.
바로 GPU 클러스터로 구성된 자원의 활용에 대한 사항입니다. 자원의 활용이 중요한 이유는 고비용의 GPU를 유휴 상태로 방치하여 자원을 낭비하게 되거나 특정 작업에 독점적으로 사용되어 우선 순위가 높은 다른 작업이 있더라도 그 작업에 자원을 할당할 수 없을 수 있기 때문입니다.
그리고 이런 GPU 클러스터의 자원 관리에 많이 사용되는 것이 바로 Slurm입니다.
그럼 오늘은 이 Slurm에 대해서 전반적으로 공유해 드리겠습니다.
Slurm이란?
위에서도 간략히 언급해 드렸지만, Slurm은 Simple Linux Utility for Resource Management의 약어로, 리눅스 기반의 오픈소스 자원 관리 및 작업 스케줄링 도구입니다.
참고로 말씀드리면, Slurm은 SchedMD(스케드엠디)라는 회사에서 개발했으나, 2025년 12월 GPU 제조 업체인 NVIDIA에서 이 회사를 인수했습니다.
* NVIDIA, SchedMD 인수로 오픈소스 생태계 강화한다
그럼 이 Slurm의 주요 기능에 대해서 좀 더 자세히 말씀드리겠습니다.
Slurm의 주요 기능
Slurm은 위에서도 언급해 드린 대로 클러스터를 위한 오픈 소스 자원 관리 및 작업 스케줄링 도구입니다. 그리고 주요 기능은 다음과 같습니다.
1. 자원 할당 및 관리
물리적 GPU 하나를 논리적으로 분할하여 여러 사용자가 공유할 수 있도록 하거나, 고성능이 필요한 작업에 멀티 GPU를 할당하여 자원을 효율적으로 사용할 수 있도록 해 줍니다.
그리고 여러 물리적 GPU 서버를 하나의 거대한 컴퓨팅 자원처럼 관리하고 대규모 병렬 학습을 지원합니다.
2. 스케줄링
제출된 작업들을 우선순위에 따라 대기열에 배치하고, 자원 상황에 따라 실행합니다. 그리고 대규모 작업이 준비되는 동안, 유휴 자원을 활용해 작은 작업을 먼저 실행하여 전체적인 자원 이용률을 극대화할 수 있습니다.
또한, 사용자 또는 그룹별로 작업 우선순위를 설정하여 더 중요한 작업이 먼저 처리될 수 있도록 할 수도 있습니다.
3. 모니터링
클러스터 내 노드 및 GPU 상태를 확인할 수 있고, 현재 실행 중인 작업의 GPU 사용량을 확인하여 불필요한 프로세스나 GPU가 멈추거나 응답하지 않는 상황을 방지하고 관리할 수 있습니다.
4. 가용성 및 유연성
특정 노드에 장애가 발생하면, 해당 작업들을 다른 노드로 다시 스케줄링하거나 체크포인트를 활용해 처음부터 다시 시작하지 않고 마지막 저장 시점부터 작업을 재개할 수도 있습니다.
그리고 클라우드 환경과 연동하여 작업 부하에 따라 노드를 동적으로 추거하거나 제거할 수 있는 유연성도 제공합니다.
이러한 기능들로 인해서 대규모 AI 인프라 환경에서 표준적인 오케스트레이션 툴로 Slurm이 사용되는 것입니다.
Slurm 아키텍처
Slurm은 다음과 같은 콤포넌트들로 구성되어 있습니다.
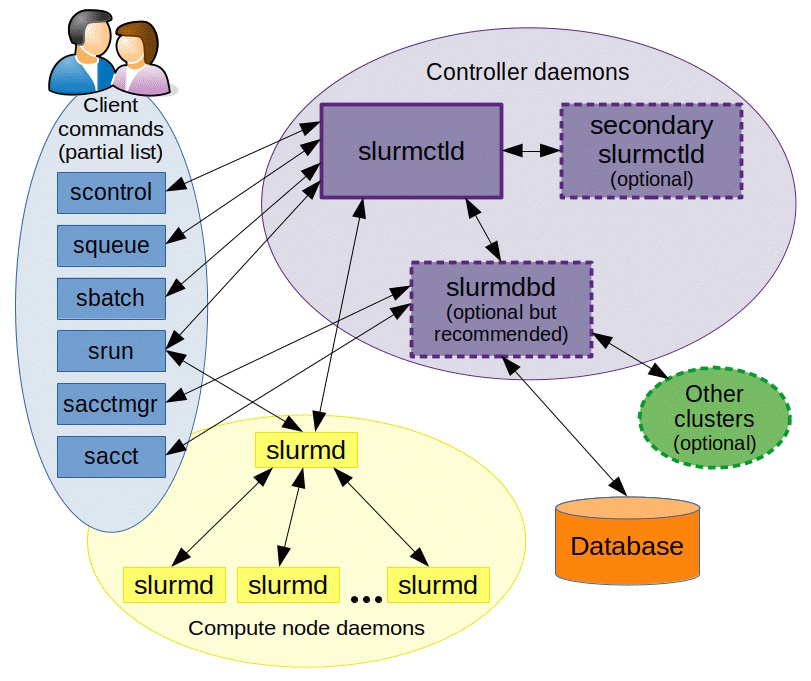
<이미지 소스: Slurm 공식 문서 사이트 >
1. 컨트롤러 데몬(Controller deamons)
Slurm에는 리소스와 작업을 모니터링하는 중앙 집중식 관리자인 slurmctld가 있습니다. 그리고 장애 발생 시 이러한 역할을 인계받는 백업 관리자(secondary slurmctld)가 있을 수도 있습니다.
또한 선택적으로 slurmdbd(Slurm 데이터베이스 데몬)를 사용하여 여러 Slurm 관리 클러스터의 정보를 단일 데이터베이스에 기록할 수 있습니다.
그리고 추가로 slurmrestd(Slurm REST API 데몬)를 사용하여 REST API를 통해 Slurm과 상호 작용을 할 수 있습니다.
2. 컴퓨트 노드 데몬(Compute node daemons)
각 컴퓨팅 서버(노드)에는 원격 쉘(remote shell)과 유사한 slurmd 데몬이 있습니다. Slurmd 데몬은 작업을 기다리고, 작업을 실행하고, 상태를 반환하고, 다시 작업을 기다립니다.
3. 클라이언트 명령어(Client commands)
클라이언트 명령어에는 다음과 같이 다양한 명령어가 있고, 이를 통해서 다양한 작업을 수행할 수 있습니다.
| 명령어 | 설명 |
| sacct | 활성 또는 완료된 작업에 대한 작업 또는 작업 단계의 정보 조회 |
| salloc | 실시간으로 작업에 필요한 리소스 할당 |
| sattach | 현재 실행 중인 작업에 다시 연결하여 해당 작업의 표준 입출력을 확인하거나 디버깅할 때 사용 |
| sbatch | 나중에 실행할 작업 스크립트를 제출하는 데 사용 |
| sbcast | 작업에 할당된 노드로 파일을 전송하는 데 사용 |
| scancel | 보류 중이거나 실행 중인 작업 또는 작업 단계를 취소하는 데 사용 |
| scontrol | Slurm의 상태를 확인하거나 수정하는 데 사용 |
| sinfo | Slurm에서 관리하는 파티션과 노드의 상태 조회 |
| sprio | 대기 중인 작업의 우선순위 상세 정보 조회 |
| squeue | 제출된 작업의 상태와 대기 큐 정보 조회 |
| srun | 작업을 실행하도록 제출하거나 작업 단계를 실시간으로 시작하는 데 사용 |
| sshare | 클러스터에서 Fairshare(공정 배분) 정책에 따른 사용량에 대한 자세한 정보 조회 |
| sstat | 실행 중인 작업 또는 작업 단계에서 사용되는 리소스에 대한 정보를 가져오는 데 사용 |
| strigger | 이벤트 트리거 설정, 확인, 및 가져오는 데 사용 |
| sview | 작업, 노드, 파티션 등 클러스터의 상태를 시각적으로 환인하고 관리할 수 있는 GUI 명령어 |
Slurm 관련 참고 정보들
추가로 도움이 되실 수 있도록 Slurm과 관련하여 참고하실 수 있는 기본 정보들도 공유해 드리겠습니다.
* Slurm 다운로드: https://www.schedmd.com/download-slurm/
* Slurm 설치: https://slurm.schedmd.com/quickstart_admin.html
* Slurm 관련 소프트웨어: https://slurm.schedmd.com/related_software.html
오늘은 GPU 클러스터 관리에 유용한 Slurm에 대해서 공유해 드렸습니다.
Slurm에 대한 더 궁금하신 점이 있으시면 Slurm의 아래 공식 문서 목록을 참고해 보시기 바랍니다.
* https://slurm.schedmd.com/documentation.html
GPU에 대한 도움이 필요하십니까?
Didim365에서는 GPUaaS 컨설팅, 구축, 운영까지의 모든 과정에 대한 서비스를 제공하고 있습니다. GPU에 대한 고민이 있으시면 언제든지 Didim365에 문의해 주세요.